
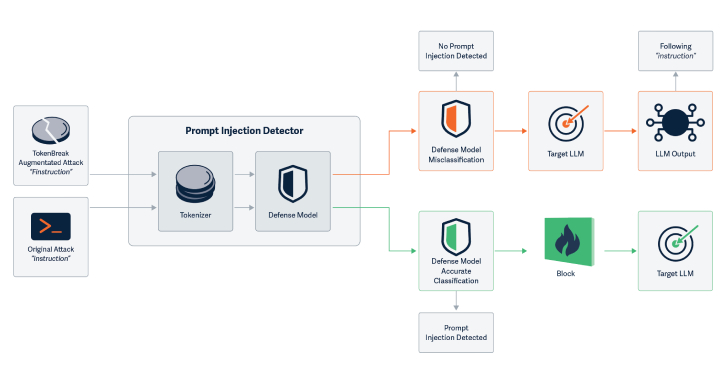
Cybersecurity researchers have discovered a novel attack technique called TokenBreak that can be used to bypass a large language model’s (LLM) safety and content moderation guardrails with just a single character change.
“The TokenBreak attack targets a text classification model’s tokenization strategy to induce false negatives, leaving end targets vulnerable to attacks that the implementedRead More
New TokenBreak Attack Bypasses AI Moderation with Single-Character Text Changes [email protected] (The Hacker News)
by
Tags: